Kompresi Data adalah salah satu subyek di bidang teknologi informasi
yang saat ini telah diterapkan secara luas. Gambar-gambar yang anda
dapatkan di berbagai situs internet pada umumnya merupakan hasil
kompresi ke dalam format GIF atau JPEG. File video MPEG adalah hasil
proses kompresi pula. Penyimpanan data berukuran besar pada server pun
seringdilakukan melalui kompresi. Sayangnya tidak banyak mata kuliah
yang memberikan perhatian pada subyek ini secara memadai. Tulisan
berikut ini akan memperkenalkan tentang dasar-dasar Kompresi Data kepada
anda.
Kompresi Data merupakan cabang ilmu komputer yang bersumber dari Teori
Informasi. Teori Informasi sendiri adalah salah satu cabang Matematika
yang berkembang sekitar akhir dekade 1940-an. Tokoh utama dari Teori
Informasi adalah Claude Shannon dari Bell Laboratory. Teori Informasi
mengfokuskan pada berbagai metode tentang informasi termasuk penyimpanan
dan pemrosesan pesan. TeoriInformasi mempelajari pula tentang
redundancy (informasi tak berguna) pada pesan.Semakin banyak redundancy
semakin besar pula ukurang pesan, upaya mengurangi redundancy inilah
yang akhirnya melahirkan subyek ilmu tentang Kompresi Data.
1. Lossy Compression
Lossy compression menyebabkan adanya perubahan data dibandingkan sebelum
dilakukan proses kompresi. Sebagai gantinya lossy compression
memberikan derajat kompresi lebih tinggi. Tipe ini cocok untuk kompresi
file suara digital dan gambar digital. File suara dan gambar secara
alamiah masih bisa digunakan walaupun tidak berada pada kondisi yang
sama sebelum dilakukan kompresi.
Sebaliknya Lossless Compression memiliki derajat kompresi yang lebih
rendah tetapi dengan akurasi data yang terjaga antara sebelum dan
sesudah proses kompresi. Kompresi ini cocok untuk basis data, dokumen
atau spreadsheet. Pada lossless compression ini tidak diijinkan ada bit
yang hilang dari data pada proses kompresi.
Secara
umum kompresi data terdiri dari dua kegiatan besar, yaitu Modeling dan
Coding. Proses dasar dari kompresi data adalah menentukan serangkaian
bagian dari data (stream of symbols) mengubahnya menjadi kode (stream of
codes). Jika proses kompresi efektif maka hasil dari stream of codes
akan lebih kecil dari segi ukuran daripada stream of symbols. Keputusan
untuk mengindentikan symbols tertentu dengan codes tertentu adalah inti
dari proses modeling. Secara umum dapat diartikan bahwa sebuah model
adalah kumpulan data dan aturan yang menentukan pasangan antara symbol
sebagai input dan code sebagai output dari proses kompresi. Sedangkan
coding adalah proses untuk menerapkan modeling tersebut menjadi sebuah
proses kompresi data.
Algoritma Kompresi
Algoritma Huffman
Algoritma ini menggunakan pengkodean yang mirip dengan kode Morse.
Berdasarkan tipe kode yang digunakan algoritma Huffman termasuk metode
statistic. Sedangkan berdasarkan teknik pengkodeannya menggunakan metode
symbolwise. Algoritma Huffman merupakan salah satu algoritma yang
digunakan untuk mengompres teks. Algoritma Huffman secara lengkap
Sebagai contoh, dalam kode ASCII string 7 huruf “ABACCDA” membutuhkan representasi 7 × 8 bit = 56 bit (7 byte), dengan rincian sebagai berikut:
01000001 01000010 01000001 01000011 01000011 01000100 01000001
A B A C C D A
Untuk
mengurangi jumlah bit yang dibutuhkan, panjang kode untuk tiap karakter
dapat dipersingkat, terutama untuk karakter yang frekuensi kemunculannya
besar. Pada string di atas, frekuensi kemunculan A = 3, B = 1, C = 2,
dan D = 1, sehingga dengan menggunakan algoritma di atas diperoleh kode
Huffman seperti pada Tabel 1.
Gambar 1. Pohon Huffman untuk “ABACCDA”

Cara Kerja :
1. Pilih dua simbol dengan peluang (probability) paling kecil (pada contoh di atas simbol B dan D). Kedua simbol tadi dikombinasikan sebagai simpul orangtua dari simbol B dan D sehingga menjadi simbol BD dengan peluang 1/7 + 1/7 = 2/7, yaitu jumlah peluang kedua anaknya.
2. Selanjutnya, pilih dua simbol berikutnya, termasuk simbol baru, yang mempunyai peluang terkecil.
3. Ulangi langkah 1 dan 2 sampai seluruh simbol habis.
Algoritma LZW (Lempel-Ziv-Welch)
Algortima
ini menggunakan teknik dictionary dalam kompresinya. Dimana string
karakter digantikan oleh kode table yang dibuat setiap ada string yang
masuk. Tabel dibuat untuk referensi masukan string selanjutnya. Ukuran
tabel dictionary pada algoritma LZW asli adalah 4096 sampel atau 12 bit,
dimana 256 sampel pertama digunakan untuk table karakter single
(Extended ASCII), dan sisanya digunakan untuk pasangan karakter atau
string dalam data input.
Algoritma
LZW melakukan kompresi dengan mengunakan kode table 256 hingga 4095
untuk mengkodekan pasangan byte atau string. Dengan metode ini banyak
string yang dapat dikodekan dengan mengacu pada string yang telah muncul
sebelumnya dalam teks.
- Fungsi/Cara Kerja :
Algoritma kompresi LZW secara lengkap :
1. KAMUS diinisialisasi dengan semua karakter dasar yang ada : {‘A’..’Z’,’a’..’z’,’0’..’9’}.
2. W <-- karakter pertama dalam stream karakter.
3. K <-- karakter berikutnya dalam stream karakter.
4. Lakukan pengecekan apakah (W+K) terdapat dalam KAMUS · Jika ya, maka W ß W + K (gabungkan W dan K menjadi string baru).
· Jika tidak, maka :
- Output sebuah kode untuk menggantikan stringW.
- Tambahkan string (W+ K) ke dalam dictionary dan berikan nomor/kode berikutnya yang belum digunakan dalam dictionary untuk string tersebut.
- W <-- K.
- Lakukan pengecekan apakah masih ada karakter berikutnya dalam stream karakter
- Jika ya, maka kembali ke langkah 2.
- Jika tidak, maka output kode yang menggantikan string W, lalu terminasi proses (stop).
Flowchart Algoritma LZW

Sebagai
contoh, string “ABBABABAC” akan dikompresi dengan LZW. Isi dictionary
pada diset dengan tiga karakter dasar yang ada: “A”, “B”, dan “C”.
Tahapan proses kompresi ditunjukkan pada Tabel dibawah ini:
Tahapan Kompresi LZW
Langkah Posisi Karakter Dictionary Output
1 1 A [4] A B [1]
2 2 B [5] B B [2]
3 3 B [6] B A [2]
4 4 A [7] A B A [4]
5 6 A [8] A B A C [7]
6 9 C - [3]
Hasil Proses Kompresi

Algoritma DMC
Algoritma
DMC (Dynamic Markov adalah algoritma kompresi data lossless
dikembangkan oleh Gordon Cormack dan Nigel Horspool. Algoritma ini
menggunakan pengkodean aritme prediksi oleh pencocokan sebagian (PPM),
kecuali bahwa input diperkirakan satu bit pada satu waktu (bukan dari
satu byte pada suatu waktu). DMC memiliki rasio kompresi yang baik dan
kecepatan moderat, mirip dengan PPM, tapi memerlukan sedikit lebih
banyak memori dan tidak diterapkan secara luas. Beberapa implementasi
baru - baru ini mencakup program kompresi eksperimental pengait oleh
Nania Francesco Antonio, ocamyd oleh Frank Schwellinger, dan sebagai
submodel di paq8l oleh Matt Mahoney. Ini didasarkan pada pelaksanaan
tahun 1993 di C oleh Gordon Cormack.
Pada DMC,
simbol alfabet input diproses per bit, bukan per byte. Setiap output
transisi menandakan berapa banyak simbol tersebut muncul. Penghitungan
tersebut dipakai untuk memperkirakan probabilitas dari transisi.
Contoh: transisi yang keluar dari state 1 diberi label 0/5, artinya bit 0
di state 1 terjadi sebanyak 5 kali. Sebuah model yang diciptakan oleh
metode DMC

Secara
umum, transisi ditandai dengan 0/p atau 1/q dimana p dan q menunjukkan
jumlah transisi dari state dengan input 0 atau 1. Nilai probabilitas
bahwa input selanjutnya bernilai 0 adalah p/(p+q) dan input selanjutnya
bernilai 1 adalah q/(p+q). Lalu bila bit sesudahnya ternyata bernilai 0,
jumlah bit 0 di transisi sekarang ditambah satu menjadi p+1. Begitu
pula bila bit sesudahnya ternyata bernilai 1, jumlah bit 1 di transisi
sekarang ditambah satu menjadi q+1. Algoritma kompresi DMC :
2. t <-- 1 (state sekarang)
3. T[1][0] = T[1][1] <-- 1 (model inisialisasi)
4. C[1][0] = C[1][1] <-- 1 (inisialisasi untuk menghindari masalah frekuensi nol)
5. Untuk setiap input bit e :
- u <-- t
- t <-- T[u][e] (ikuti transisi)
- Kodekan e dengan probabilitas : C[u][e] / (C[u][0] + C[u][1])
- C[u][e] <-- C[u][e]+1
- Jika ambang batas cloning tercapai, maka :
- s <-- s + 1 (state baru t’)
- T[u][e] <-- s ; T[s][0] <-- T[t][0] ; T[s][1] <-- T[t][1]
- Pindahkan beberapa dari C[t] ke C[s]
Perbandingan Kinerja Algoritma Huffman dengan Algoritma LZW dan DMC
Jika kinerja algoritma Huffman dibandingkan dengan Algoritma LZW dan DMC, maka akan diperoleh hasil seperti dibawah ini [6] :
Box Plot Rasio Kompresi Algoritma Huffman, LZW dan DMC

Box Plot Kecepatan Kompresi Algoritma Huffman, LZW dan DMC

Grafik Perbandingan Rasio Kompresi Algoritma Huffman, LZW dan DMC

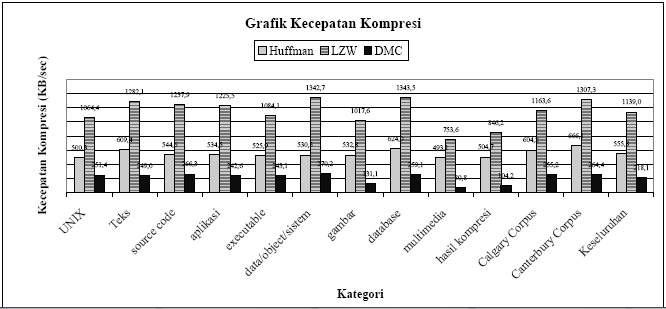
Grafik Perbandingan Kecepatan Kompresi Algoritma Huffman, LZW dan DMC
KESIMPULAN
Dari artikel ini, dapat diambil kesimpulan sebagai berikut :
1. Secara rata-rata algoritma DMC menghasilkan rasio file hasil kompresi yang terbaik (41.5% ± 25.9), diikuti algoritma LZW (60.2% ± 28.9) dan terakhir algoritma Huffman (71.4% ± 15.4)
2. Algoritma Huffman dapat digunakan sebagai dasar untuk kompresi data, dan pengaplikasiannya cukup mudah serta dapat digunakan dalam berbagai jenis data.
3. Secara rata-rata algoritma LZW membutuhkan waktu kompresi yang tersingkat (kecepatan kompresinya = 1139 KByte/sec ± 192,5), diikuti oleh algoritma Huffman (555,8 KByte/sec ± 55,8), dan terakhir DMC (218,1 KByte/sec ± 69,4). DMC mengorbankan kecepatan kompresi untuk mendapatkan rasio hasil kompresi yang baik. File yang berukuran sangat besar membutuhkan waktu yang sangat lama bila dikompresi dengan DMC.
4. Jika dibandingkan dengan algoritma LZW dan DMC,dalam kompresi data, algoritma Huffman masih kalah dalam hal rasio kompresi data maupun kecepatan kompresinya.
REFERENSI :
http://datacompression.info/huffiman.shtml
http://en.wikipedia.org/wiki/Lossless_data_compression










0 komentar:
Posting Komentar